As a registered student at the VU, you can enroll in almost eny course offered. While some courses have prerequisites (accounting I before accounting II), and some are restriced to specific study programs (applied surgery), generally, you are free to follow courses on any topic you like.
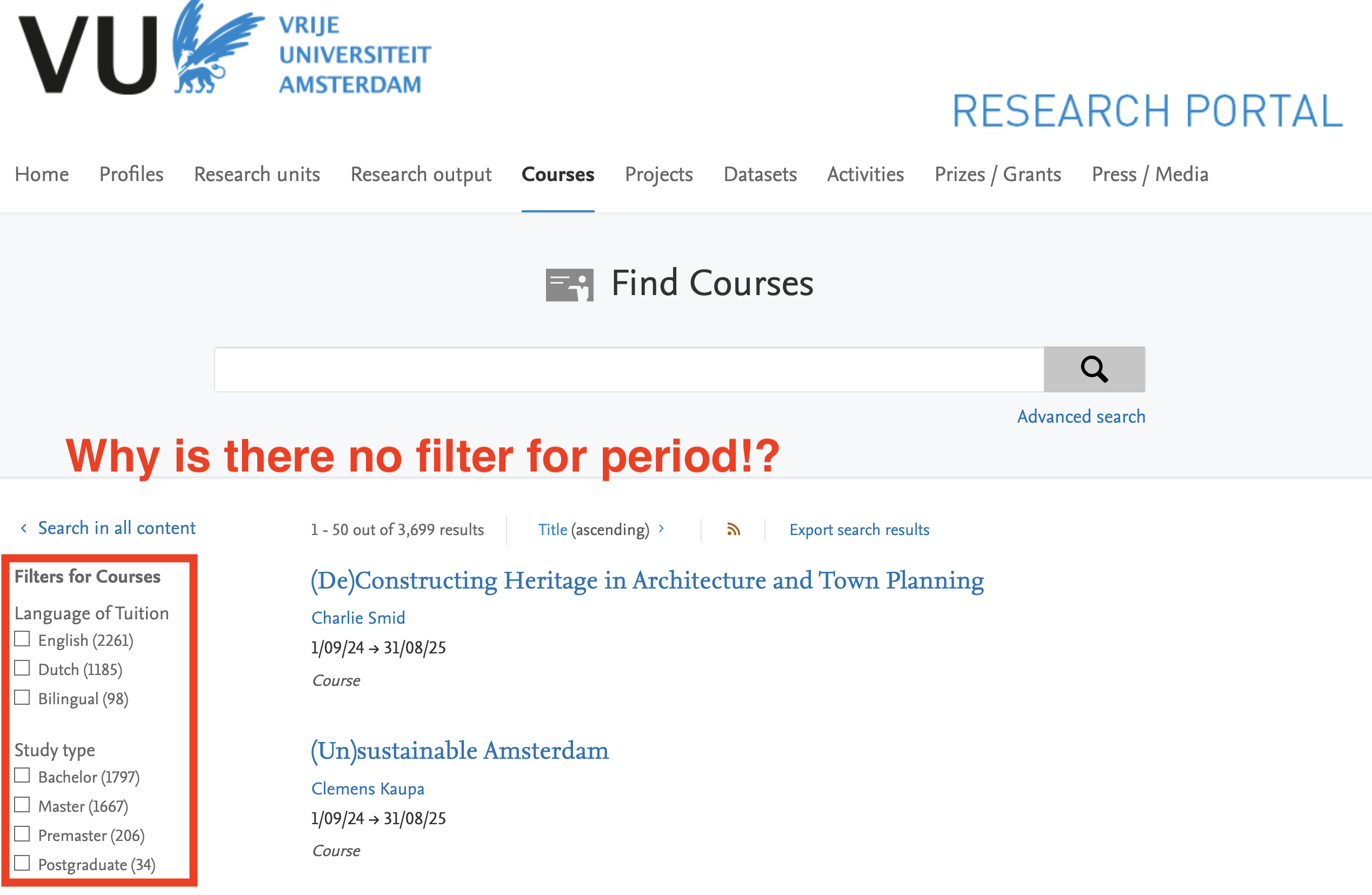
For the motivated students this opens an opportunity to “misuse” the system and enroll in as many courses as possible. I haven’t found a hard limit, altough the VU sends a warning mail concerning your mental wellbeing after enrolling for more than 18 ECTS of courses. Unfortunately, the logistics of planning all these courses is quite a hassle, as browsing the VU studiegids can be quite a hassle. The platform only shows 50 results per page, lacks the ability to filter courses by semester/period, and checking whether a course is open for enrollment requires several clicks.
This presented the perfect opportunity to practice some web scraping skills and build a queryable overview of all the VU courses using R
Follow the links to the GitHub repository, and final_results.csv
Implementation using R
Lets start by cleaning the workspace and loading required dependencies
# a nice function to clear the worksapce and install + load required packages
# Clear workspace
rm(list = ls())
# Function to load packages, and install them if necessary.
install_and_load <- function(packages) {
installed_packages <- rownames(installed.packages()) # Check installed packages
to_install <- packages[!(packages %in% installed_packages)]
if (length(to_install) > 0) { # Install missing
install.packages(to_install, dependencies = TRUE)
}
suppressMessages(lapply(packages, require, character.only = TRUE, quietly = TRUE)) # Load
}
install_and_load(c("xml2", "rvest", "dplyr"))Lets scrape all URL’s linking to course pages from the search page. As only 2500 out of ~3600 pages are returend, we have to request all courses both ascendingly and descendingly. We can filter for duplacates later.
# Initialize base URLs and page numbers
asc_url <- "https://research.vu.nl/en/courses/?year=2024&ordering=title&descending=false&format=rss&page="
desc_url <- "https://research.vu.nl/en/courses/?year=2024&ordering=title&descending=true&format=rss&page="
url_incr <- 0:49 # Assuming pagination goes from page 0 to 49
# Define a function to fetch links from RSS feed pages
fetch_links <- function(base_url, url_incr) {
links_list <- list()
# Loop through each page
for (i in url_incr) {
# Construct the full URL for the current page
url <- paste0(base_url, i)
# Read the RSS feed XML content
rss_content <- read_xml(url)
# Extract all <link> elements
links <- xml_find_all(rss_content, ".//link")
# exclude first link
link_texts <- xml_text(links[-1])
# Here all new links are appended. Could optimize by initializing length first. but at 3k entries this shouldn't be an issue. I'm just lazy here
links_list[[i + 1]] <- link_texts
# A small delay to avoid overloading the server. Was expecting to be rate limited but 0.1 seemed just fine
Sys.sleep(0.1)
}
# Return the combined list of links
return(unlist(links_list))
}
asc_links <- fetch_links(asc_url, url_incr)
desc_links <- fetch_links(desc_url, url_incr)
# Filter for duplicates and show some results
all_links <- unique(c(asc_links, desc_links))
head(all_links)
# Some code to save and load all links as RDS data so the VU site only had to be scraped once.
# save all_links to an file
# saveRDS(all_links, "all_links.RDS")These url’s all lead to research.vu.nl pages that contain many different links. We are only interested in links containing “studiegids”. lets loop through all pages and store all links containing “studielink” and thus lead to the information page.
studiegids_links <- vector("character", length = 3575)
counter <- 1
for (url in all_links) {
tryCatch({
# Read HTML of reasearch.vu
html_content <- read_html(url)
# Look for node with link to studiegids
studiegids_nodes <- html_nodes(html_content, xpath = "//h2[@class='subheader' and text()='URL study guide']/following-sibling::a[1]")
# Extract href
href_values <- html_attr(studiegids_nodes, "href")
studiegids_links[[counter]] <- href_values
# Print progress every 10 iterations
if (counter %% 10 == 0) {
cat("Processed", counter, "out of", length(all_links), "URLs\n")
}
# Increment the counter only if tryCatch was successful
counter <- counter + 1
}, error = function(e) {
# error message
message("Error in URL: ", url)
})
}
studiegids_links <- unlist(studiegids_links)
head(studiegids_links)
# Some code to save and load all links as RDS data so the VU site only had to be scraped once.
# Save studiegids_links to an R file
# saveRDS(studiegids_links, "studiegids_links.RDS") # saving results in between here. Each of the links in the list “studiegids_links” links to a webpage with the info we want to scrape. I’d like to scrape the following data into a dataframe:
- Course Title (separate div)
- “Course Code”
- “Credits”
- “Period”
- “Course Level”
- “Faculty”
- “Course Coordinator”
- “Examiner”
- “Teaching staff”
There also is a <div class=”h3 course-data-header”>Target audiences</div>. I would like all the text values of the href’s that are child elements of it. Store them into one column.
If there exists an <h3>Entry Requirements</h3> I would like the text value of its child element (<p>) If there exists an <h3>Course Content</h3> I would like the text value of its child element (<p>)
Finally, also store the link used to access it in the dataframe.
# Number of pages to scrape
num_pages <- 3526 # might change. In hindsight I should have called length() to determine this
# Initialize an empty dataframe of 3526 rows x 13 columns. This time I wasn't lazy :)
data <- data.frame(
Title = rep("", num_pages),
Course_code = rep("", num_pages),
Credits = rep("", num_pages),
Period = rep("", num_pages),
Course_Level = rep("", num_pages),
Faculty = rep("", num_pages),
Course_Coordinator = rep("", num_pages),
Examiner = rep("", num_pages),
Teaching_Staff = rep("", num_pages),
Target_Audiences = rep("", num_pages),
Entry_Requirements = rep("", num_pages),
Course_Content = rep("", num_pages),
URL = rep("", num_pages),
stringsAsFactors = FALSE
)
# Global counter for progress
i <- 1 # Start from the first row
# Define a function to scrape data from a single URL and fill the dataframe row by row
scrape_course_data <- function(url) {
tryCatch({
# Read the HTML content of the page
page <- read_html(url)
# Course title
course_title <- page %>%
html_node("#title h2") %>%
html_text(trim = TRUE)
# Course data table (if it exists)
course_data_node <- page %>%
html_node(".course-data")
# If the course data table exists, extract it as a data frame
course_data <- course_data_node %>% html_table(header = FALSE, fill = TRUE)
# Extract details from course data table
course_code <- as.character(course_data[1, 2])
credits <- as.character(course_data[2, 2])
period <- as.character(course_data[3, 2])
course_level <- as.character(course_data[4, 2])
faculty <- as.character(course_data[5, 2])
course_coordinator <- as.character(course_data[6, 2])
examiner <- as.character(course_data[7, 2])
teaching_staff <- as.character(course_data[8, 2])
# Extract Target Audiences under <div class="h3 course-data-header">Target audiences</div>
target_audiences <- page %>%
html_node(xpath = "//div[@class='h3 course-data-header' and contains(text(), 'Target audiences')]/following-sibling::div") %>%
html_nodes("a") %>%
html_text(trim = TRUE) %>%
paste(collapse = ", ") # Combine into a single string
# Extract Entry Requirements text, if it exists
entry_requirements <- page %>%
html_node(xpath = "//h3[contains(text(), 'Entry Requirements')]/following-sibling::p") %>%
html_text(trim = TRUE) %>%
{if (is.null(.)) NA else .}
# Extract Course Content text, if it exists
course_content <- page %>%
html_node(xpath = "//h3[contains(text(), 'Course Content')]/following-sibling::p") %>%
html_text(trim = TRUE) %>%
{if (is.null(.)) NA else .}
# Increment counter and show progress
cat("Scraped page", i, ":", url, "\n")
# fill dataframe with scraped data
data[i, ] <<- c(course_title, course_code, credits, period, course_level, faculty,
course_coordinator, examiner, teaching_staff, target_audiences,
entry_requirements, course_content, url)
i <<- i + 1
}, error = function(e) {
# error handling
cat("Error scraping", url, "\n")
})
}
# Now run for each url we gathered
for (url in studiegids_links) {
scrape_course_data(url)
}
# Final dataframe!
head(data)
write.csv(data, "VU_courses", row.names = FALSE)The script takes some time to run, especially as we don’t want to get flagged by overloading the server with requests. However, after a while, we have a nice dataframe with all the courses offered by the VU, wich we can query as intended!
Follow the links to the GitHub repository, and final_results.csv
