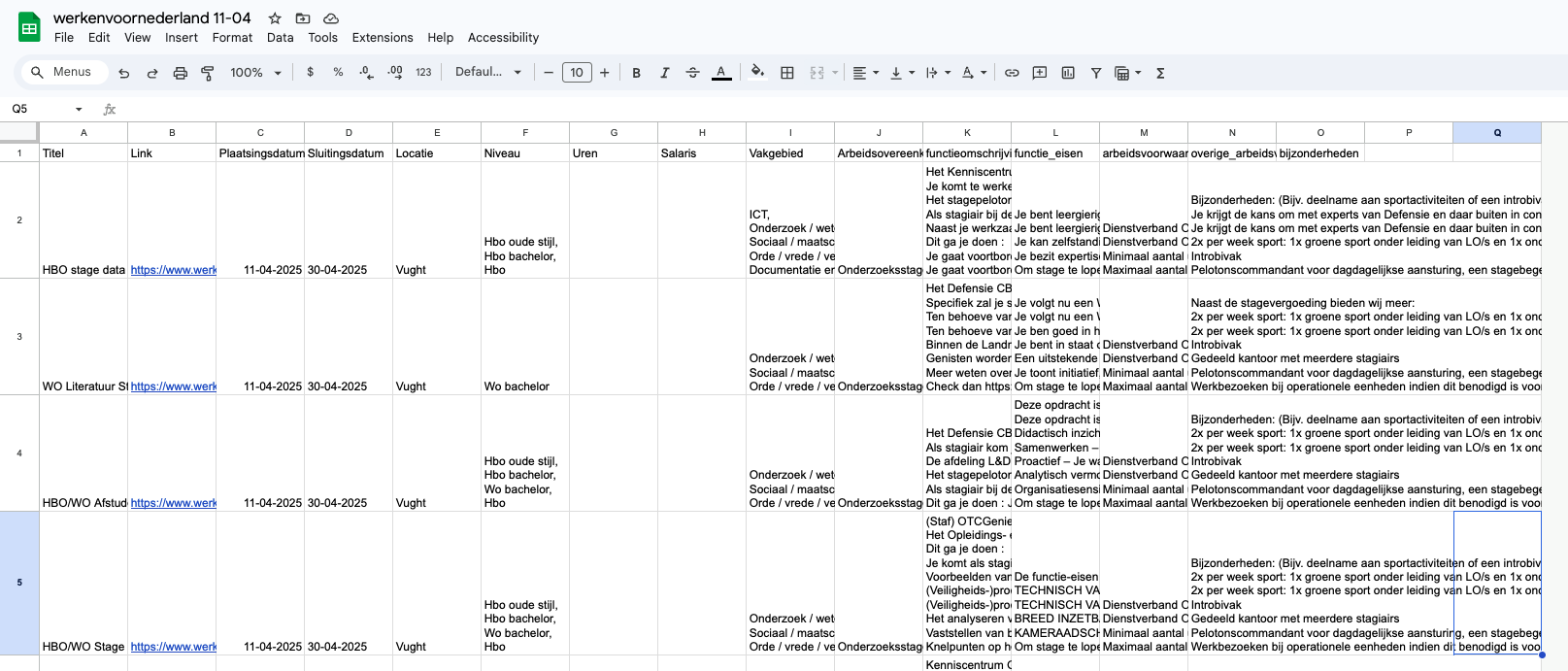
As I’m graduating and entering the job market, I entertain the idea of working for the Dutch government. While looking through the job vacancies on werkenvoornederland.nl I wanted to filter on more specific criteria, and was curios about the trends and requirements for different departments. I figured it would be helpfull for my search to scrape the site, and intresting to get a better overview of the job market.
The scraped data is published here (google sheets). Last update 11 April 2025. Below is the code I used to scrape the data if you want to try it yourself.
I’m still working on automating the process with a github action or cron job on my raspberry pi so I can update the data daily.
While I have little ethical objections to scraping the site, I do have concerns about automating the application process. Spinning up a selenium project with an AI model to send out personalized applications for each vacancy doesn’t seem like too hard, but I prefer having to keep some thought into the applications for now.
Fetch all vacancies URLs
import requests
from bs4 import BeautifulSoup
from bs4 import NavigableString
import pandas as pd
from datetime import datetime
import os
import random
import time
BASE_URL = "https://www.werkenvoornederland.nl"
OUTPUT_FILE = "output.csv"
ARCHIVE_FILE = "output_archive.csv"
ALL_FIELDS = [
"Titel", "Link", "Plaatsingsdatum", "Sluitingsdatum",
"Locatie", "Niveau", "Uren", "Salaris", "Vakgebied", "Arbeidsovereenkomst"
]
DUTCH_MONTHS = {
"januari": "01", "februari": "02", "maart": "03", "april": "04",
"mei": "05", "juni": "06", "juli": "07", "augustus": "08",
"september": "09", "oktober": "10", "november": "11", "december": "12"
}
# Dutch date to dd-mm-yyyy
def convert_dutch_date(date_str):
parts = date_str.strip().lower().split()
if len(parts) == 3:
day, month_dutch, year = parts
month = DUTCH_MONTHS.get(month_dutch.lower(), "01")
return f"{day.zfill(2)}-{month}-{year}"
return None
# Fetch vacancies list
def fetch_vacancies(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
vacancies = []
today = datetime.today()
for section in soup.find_all("section", class_="vacancy"):
title_tag = section.find("h2", class_="vacancy__title").find("a")
title = title_tag.text.strip()
relative_link = title_tag.get("href")
full_link = BASE_URL + relative_link
plaatsingsdatum = ""
top_info = section.find("div", class_="job-short-info__top")
if top_info:
for line in top_info.stripped_strings:
if "Plaatsingsdatum:" in line:
raw_date = line.replace("Plaatsingsdatum:", "").strip()
plaatsingsdatum = convert_dutch_date(raw_date)
sluitingsdatum = ""
sluiting_tag = section.find("span", class_="vacancy-publication-end")
if sluiting_tag:
text = sluiting_tag.text.strip()
if "voor" in text:
raw_date = text.split("voor", 1)[-1].strip()
sluitingsdatum = convert_dutch_date(raw_date)
try:
sluitingsdatum_obj = datetime.strptime(sluitingsdatum, "%d-%m-%Y")
if sluitingsdatum_obj < today:
continue
except:
continue
vacancies.append({
"Titel": title,
"Link": full_link,
"Plaatsingsdatum": plaatsingsdatum,
"Sluitingsdatum": sluitingsdatum,
"Locatie": None,
"Niveau": None,
"Uren": None,
"Salaris": None,
"Vakgebied": None,
"Arbeidsovereenkomst": None
})
return vacancies
# LOGIC
existing_data = pd.DataFrame()
today = datetime.today().date()
# Load existing data
if os.path.exists(OUTPUT_FILE):
existing_data = pd.read_csv(OUTPUT_FILE)
existing_data["Sluitingsdatum"] = pd.to_datetime(existing_data["Sluitingsdatum"], format="%d-%m-%Y", errors="coerce")
existing_data["Plaatsingsdatum"] = pd.to_datetime(existing_data["Plaatsingsdatum"], format="%d-%m-%Y", errors="coerce")
# Identify expired vacancies
expired_vacancies = existing_data[existing_data["Sluitingsdatum"].dt.date <= today]
# Archive expired vacancies
if not expired_vacancies.empty:
if os.path.exists(ARCHIVE_FILE):
archive_df = pd.read_csv(ARCHIVE_FILE)
archive_df = pd.concat([archive_df, expired_vacancies])
archive_df.drop_duplicates(subset=["Titel", "Link"], inplace=True)
else:
archive_df = expired_vacancies
archive_df.to_csv(ARCHIVE_FILE, index=False, encoding="utf-8-sig")
print(f"Archived {len(expired_vacancies)} expired vacancies.")
# Keep only active vacancies
existing_data = existing_data[existing_data["Sluitingsdatum"].dt.date > today]
print(f"Local data loaded: {len(existing_data)} active vacancies.")
# Pages to scrape (check if todays vacancies are already scraped)
use_page_2 = False
if not existing_data.empty and (existing_data["Plaatsingsdatum"].dt.date == today).any():
use_page_2 = True
url = f"{BASE_URL}/vacatures?pagina=1" if use_page_2 else f"{BASE_URL}/vacatures?pagina={random.randint(200, 250)}"
print(f"Scraping {url}")
# Fetch
new_vacancies = fetch_vacancies(url)
df_new = pd.DataFrame(new_vacancies)
# Merge, omit duplicates
if not existing_data.empty:
combined = pd.concat([existing_data, df_new])
combined.drop_duplicates(subset=["Titel", "Link"], inplace=True)
else:
combined = df_new
combined = combined.reindex(columns=ALL_FIELDS)
combined.to_csv(OUTPUT_FILE, index=False, encoding="utf-8-sig")
print(f"Saved {len(combined)} active vacancies.")Fetch details for each vacancy
# Load CSV
OUTPUT_FILE = "output.csv"
combined = pd.read_csv(OUTPUT_FILE, encoding="utf-8-sig")
combined.fillna("", inplace=True)
# Track all columns dynamically (possibly the accordion sections differ)
ALL_FIELDS = list(combined.columns)
# normalize title fields
def normalize_title(title):
return title.lower().replace(" ", "_").replace("-", "_").replace("", "_")
# scrape dynamic 'accordion' sections
def scrape_accordion_sections(soup):
accordion_data = {}
accordion_div = soup.find("div", {"id": "accordionGroup"})
if accordion_div:
items = accordion_div.find_all("div", class_="Accordion-panel")
for panel in items:
try:
button = panel.find_previous("button")
if button:
raw_title = button.get("data-item") or button.get_text(strip=True)
title = normalize_title(raw_title)
content_div = panel.find("div", class_="s-article-content")
if content_div:
text_parts = []
for tag in content_div.find_all(["p", "li", "ul"], recursive=True):
text = tag.get_text(strip=True, separator=" ")
if text:
text_parts.append(text)
accordion_data[title] = "\n".join(text_parts)
except Exception as e:
print(f"Error parsing accordion section: {e}")
return accordion_data
# Scrape individual page info
def scrape_details(row):
link = row["Link"]
print(f"Scraping details from {link}")
try:
response = requests.get(link)
soup = BeautifulSoup(response.content, "html.parser")
# LOCATIE
locatie = None
locatie_span = soup.find("span", {"title": "Locatie"})
if locatie_span:
sibling = locatie_span.find_next_sibling("span")
if sibling:
locatie = sibling.get_text(strip=True)
# NIVEAU
niveau = None
niveau_span = soup.find("span", {"title": "Niveau"})
if niveau_span:
sibling = niveau_span.find_next_sibling("span")
if sibling:
niveau = sibling.get_text(strip=True)
# SALARIS
salaris = None
salaris_span = soup.find("span", {"title": "Salaris"})
if salaris_span:
value_container = salaris_span.find_next_sibling("span")
if value_container:
salaris = " ".join(value_container.stripped_strings)
# VAKGEBIED
vakgebied = None
vakgebied_span = soup.find("span", {"title": "Vakgebied"})
if vakgebied_span:
sibling = vakgebied_span.find_next_sibling("span")
if sibling:
vakgebied = sibling.get_text(strip=True)
# ARBEIDSOVEREENKOMST
arbeidsovereenkomst = None
arbeid_span = soup.find("span", {"title": "Arbeidsovereenkomst"})
if arbeid_span:
sibling = arbeid_span.find_next_sibling("span")
if sibling:
arbeidsovereenkomst = sibling.get_text(strip=True)
# update basic fields
row["Locatie"] = locatie
row["Niveau"] = niveau
row["Salaris"] = salaris
row["Vakgebied"] = vakgebied
row["Arbeidsovereenkomst"] = arbeidsovereenkomst
# scrape accordion content
accordion_sections = scrape_accordion_sections(soup)
# add dynamic fields to the row
for key, value in accordion_sections.items():
row[key] = value
if key not in ALL_FIELDS:
ALL_FIELDS.append(key)
except Exception as e:
print(f"Failed to scrape {link}: {e}")
return row
# process each row that needs scraping
for idx, row in combined.iterrows():
print(f"[{idx+1}/{len(combined)}] Checking: {row['Titel']}")
if row["Locatie"] == "" and row["Uren"] == "" and row["Salaris"] == "":
updated_row = scrape_details(row)
# update fixed fields
for field in ["Locatie", "Niveau", "Salaris", "Vakgebied", "Arbeidsovereenkomst"]:
combined.at[idx, field] = updated_row.get(field, "")
# ypdate dynamic accordion fields
for key in updated_row.keys():
if key not in combined.columns:
combined[key] = "" # create column if missing
combined.at[idx, key] = updated_row[key]
# save data (after each scrape so we can quit safely)
combined.to_csv(OUTPUT_FILE, index=False, encoding="utf-8-sig")
print(f"Updated: {row['Titel']}")
time.sleep(random.randint(1, 5)) # Rate limit
print("done scraping missing details!")